多表查询怎么搞?数据库里各种表关联那些事儿,聊聊不同数据库的区别和用法

说到多表查询,这其实就是数据库里最核心、也最让人头大的事儿之一,你想想,一个系统里,用户信息放一张表,订单信息放另一张表,商品信息又放一张表,你想看“张三买了哪些商品”,这就得把三张表的信息拼到一起看,这个“拼”的过程,就是多表查询。
核心思想:表关联
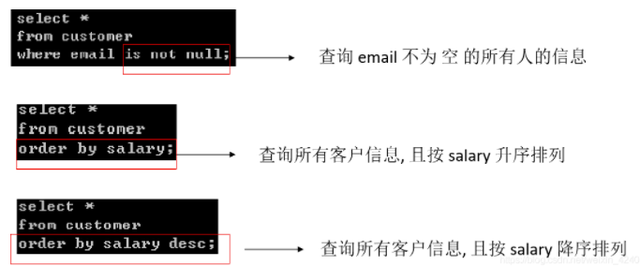
多表查询的灵魂在于“关联”,就像用一根线,把两张表里有关联的数据穿起来,这根“线”就是两个表都有的那个字段,用户ID”,用户表里有“用户ID”和“用户名”,订单表里也有“用户ID”和“订单号”,通过共同的“用户ID”,我们就能知道哪个订单是哪个用户下的。
几种主要的关联方式(JOIN)

关联方式有好几种,最常用的是下面这四种,理解它们的关键是想象两张表——假设左边是表A,右边是表B。
-
内连接(INNER JOIN):这是最常用的一种,它只把两张表里能“连线”成功的记录找出来,表A(用户)和表B(订单)做内连接,结果里只会有那些在用户表里有记录、同时在订单表里也有他订单的用户,如果一个新用户从来没下过单,他在订单表里没有记录,那他就不会出现在结果里,内连接求的是“交集”。(根据关系数据库理论基础中的连接操作定义)
-
左连接(LEFT JOIN):也叫左外连接,它是以左边的表(表A)为基准,结果里会包含左边表的所有记录,不管它在右边的表里有没有找到能“连线”的,如果右边表里没有匹配的记录,那么右边表的那些字段就显示为空(NULL),还拿用户和订单举例,左连接的结果会列出所有用户,包括那些没下过单的,对于没下单的用户,他的订单信息那边就是空的,这在统计“每个用户的订单情况,包括零订单的用户”时特别有用。

-
右连接(RIGHT JOIN):和左连接反过来,以右边的表(表B)为基准,结果包含右边表的所有记录,再去匹配左边的表,左边表匹配不上的地方就显示NULL,实际工作中,左连接用得远比右连接多,因为通常我们心里都有一个主次关系,用左连接调整一下表的顺序就能达到目的,所以右连接有时会被有意避免,让代码更统一好懂。
-
全外连接(FULL OUTER JOIN):这个是把左连接和右连接的结果合在一起,它会返回左右两表中所有的记录,当某一边没有匹配时,另一边就显示NULL,相当于求的是“并集”,同时能看到所有用户和所有订单的关联情况,这种连接对数据库性能消耗比较大,用得相对少一些。(基于SQL标准中对JOIN类型的描述)
不同数据库的小区别

虽然上面这些核心概念在所有主流数据库(如MySQL、PostgreSQL、SQL Server、Oracle)里都是一样的,但确实有一些细微的语法和功能差别。
-
MySQL:可以说是最普及的数据库了,尤其是在Web应用里,它对标准SQL的支持很全面,但历史上有一个小特点:它曾经不完全支持“全外连接”(FULL OUTER JOIN),虽然在较新的版本中可能已经支持,但在很长一段时间里,很多人习惯用“左连接 + 右连接 UNION 合并”的方式来模拟实现全外连接,所以如果你在MySQL的老代码里看不到FULL JOIN,别奇怪。(根据MySQL官方文档关于JOIN语法的历史变更说明)
-
PostgreSQL:以严格遵守SQL标准而闻名,上面说的所有连接方式,它都支持得很好,而且PostgreSQL在处理复杂查询和数据分析方面性能非常强劲,尤其擅长处理那种涉及多表关联的复杂分析型查询,如果你做的查询特别复杂,PostgreSQL可能会表现得比MySQL更稳定、更快。
-
SQL Server 和 Oracle:这两个是商业数据库里的老大哥,功能极其强大和完整,对于多表查询,它们不仅完全支持所有标准JOIN,还提供了一些自己独有的、更高级的关联语法或查询提示(Hints),让资深的数据库管理员(DBA)能更精细地控制查询的执行过程,从而优化性能,不过这些高级功能通常在学习初期用不到。
总结一下
多表查询就是通过JOIN把有关系的表连起来,内连接最常用,要的是两边都有的数据;左连接是以左表为主,保证左表数据不丢失;全连接是两边数据都要,不同的数据库在基本用法上大同小异,主要是语法细节和对高级功能的支持程度有差别,MySQL更亲民普及,PostgreSQL在复杂查询上可能更胜一筹,而SQL Server和Oracle则提供了企业级的高级功能,刚开始学,先把几种JOIN的逻辑搞清楚,这是放之四海而皆准的道理,换哪个数据库都一样。
本文由盘雅霜于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/79005.html
相关文章
-
ORA-31101报错锁资源失败问题分析及远程快速修复方法分享
-
MySQL数据库安全那些事儿,渗透测试和漏洞利用的零散总结分享
-
微软面对Azure里那几个超级棘手的云安全漏洞,到底怎么应对的?
-

Redis源码改多线程升级,想法和实现还在摸索中
-
打造属于你的影像库,轻松存储管理那些珍贵的照片和视频
-

ORA-32489报错原因和解决办法,WITH子句列别名没对应导致排序失败远程协助处理
-

MySQL报错ER_RPL_CORRUPTED_INFO_TABLE,远程帮忙修复故障怎么搞
-
ORA-19966报错说ALTER DATABASE RECOVER STANDBY DATAFILE不能用了,远程修复遇到的坑和解决办法分享