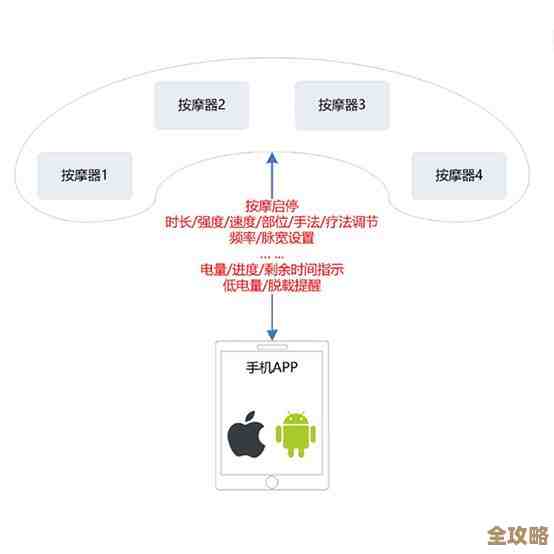
数据库脱敏其实就是为了保护隐私,避免数据泄露的那些方法和实践分享

根据中国网络安全领域专家左耳朵耗子在其个人技术分享中的观点,数据库脱敏的核心目标非常简单直接,就是为了在需要使用数据的时候,不让不该看到敏感信息的人看到这些信息,这就像给数据戴上了一副“面具”,既保留了数据的样子和用途,又隐藏了其真实的身份。
为什么脱敏如此重要?
想象一下,公司里的开发人员需要用一个真实的数据库副本来测试新开发的软件功能,如果这个测试数据库里包含所有用户的真实姓名、身份证号、手机号和银行卡号,风险就非常大了,一旦这个测试环境被不当访问,或者有内部人员心怀不轨,就会导致大规模的数据泄露,这样的新闻我们经常看到,后果非常严重,脱敏不是可选项,而是保护用户隐私和遵守法律法规(比如中国的《网络安全法》和《个人信息保护法》)的必选项。
常见的脱敏方法与实践
这些方法听起来可能有些技术名词,但理解起来并不复杂,根据常见的行业实践,主要包括以下几种:
-
替换: 这是最直观的方法,就是把真实的敏感数据替换成看起来像那么回事的假数据,把真实的姓名“张三”替换成“李四”,把身份证号“110101199001011234”替换成“310105198502028765”,这种方法的好处是,数据格式保持不变,测试程序能够正常校验格式,但信息本身完全是假的,有时候会使用从一份虚构数据列表中随机选取的方式,也有时候会使用一种可逆的算法(例如密码学中的哈希函数,但这里不深入探讨)来确保相同的真值总是被替换成相同的假值,这在某些需要关联数据的测试中很有用。
-
乱序: 把某一列数据内部的顺序打乱,将一个用户表中的所有手机号随机重新排列,这样,原来对应着张三的那个手机号,现在可能对应李四了,真实的数据依然存在,但关联关系被破坏了,无法通过手机号反推出具体的个人,这种方法简单快捷,但需要注意,如果其他关联表没有同步乱序,可能会造成数据混乱。
-
遮蔽或打码: 这是我们日常生活中最常见的方法,就像快递单上隐藏部分手机号一样,在数据库中,可以只显示数据的部分字符,其余用特定符号(如*或X)代替,身份证号显示为“1101011234”,邮箱显示为“z***@example.com”,这种方法非常安全,因为被遮蔽的部分几乎不可恢复,但缺点是数据变得不完整,可能不适合需要完整数据格式的测试场景。
-
泛化: 通过降低数据的精度或粒度来保护隐私,将具体的出生日期“1990年1月1日”泛化为“1990年”,或者将精确的年薪“125,000元”泛化为一个区间“10万-15万”,这样既保留了一定的统计和分析价值,又避免定位到具体个人,在需要发布统计报告或进行大数据分析时,这种方法很常用。
-
仿真生成: 利用工具根据预定义的规则,批量生成完全虚构但符合逻辑的数据,生成一批虚拟的用户信息,包括姓名、年龄、地址等,这些数据在现实中不存在,但彼此之间是关联合理的(如同一个城市的地址邮编匹配),这是目前越来越受欢迎的方式,因为它彻底脱离了原始真实数据,从源头上杜绝了泄露的可能。
实践中需要注意什么?
仅仅知道方法还不够,在实际操作中,有几个关键点需要牢记。脱敏必须是自动化的,不能依赖人工手动处理,因为人为操作容易出错和遗漏,需要借助专门的脱敏工具或脚本。脱敏过程需要可重复和一致,今天脱敏后的测试数据,明天应该还能以同样的方式复现,否则会给测试工作带来麻烦。要明确脱敏策略,即什么样的数据需要脱敏,采用哪种方法,脱敏到什么程度,这需要业务部门、法务部门和技术部门共同商定,也是左耳朵耗子特别强调的一点,要对脱敏后的数据进行检查和验证,确保脱敏是彻底和有效的,防止出现“假脱敏”或意外泄露的情况。
数据库脱敏是一套组合拳,它通过多种技术手段,在保障数据可用性的前提下,最大限度地降低隐私数据在开发、测试、分析和共享等环节中的泄露风险,它不是一项一劳永逸的工作,而是一个需要持续管理和优化的安全实践过程。

本文由歧云亭于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/80075.html