用Redis怎么搞精准重复数据去重,实际操作里那些细节你得知道

关于用Redis实现精准去重,实际操作中的关键细节,主要参考了Redis官方文档对SET和BITMAP数据结构的说明,以及一些技术社区如Stack Overflow上关于大规模数据去重时内存优化的讨论。

核心思想:利用Redis的Set集合 最直接想到的方法就是用Redis的Set(集合),Set的特点就是里面的元素都是唯一的,自动帮你去重,操作起来非常简单:
- 当你有一条新数据需要判断是否重复时,比如一条内容的唯一ID或者其MD5哈希值,你把它当作一个成员(member)。
- 使用
SADD key member命令尝试将这个成员添加到指定的Set中。 - 命令执行后,返回值是关键:如果返回1,说明这个成员之前不存在,添加成功,意味着这条数据是新的,不重复,如果返回0,说明这个成员已经存在于Set中了,添加失败,意味着这条数据是重复的。
这个方法简单明了,精准度是100%,因为你是基于唯一标识来判断的。这里第一个实际细节就来了:内存消耗。 如果你要去重的数据量非常大,比如上亿条,那么存储这么多字符串成员的Set会占用巨大的内存空间,成本会非常高。

应对海量数据:位图(Bitmap)的妙用 当数据量巨大,且数据的唯一ID是连续的整数(比如用户ID、自增的业务ID)时,位图(Bitmap)是节省内存的神器,位图的本质就是一个由二进制位(0和1)组成的大数组,你可以通过偏移量(offset)来操作其中的每一位。 怎么用于去重呢?
- 把每个数据的唯一ID直接当作偏移量,比如ID为10086的数据,我们就去操作第10086个二进制位。
- 使用
SETBIT key offset 1命令,这个命令的作用是将指定偏移量上的位设置为1。 - 判断是否重复时,使用
GETBIT key offset命令,如果返回1,说明这个位置之前已经被设置过了,数据重复,如果返回0,说明是新的,然后你再用SETBIT把它设为1。
位图为什么省内存?因为它用一位(bit)就能表示一个ID是否存在,对比Set存储一个整数字符串(10086"可能要占5个字节,即40位),内存节省是数量级的。但这里第二个关键细节是:位图的前提是偏移量(ID)必须是连续或大致连续的整数。 如果你的业务ID是UUID这种随机字符串,直接用作偏移量会导致位图巨大且稀疏,反而更浪费内存,这种情况下就不适合用位图。
折中方案:布隆过滤器(Bloom Filter) 当数据量海量,且唯一ID又不是数字或者不连续时,前面两种方法都有局限,这时布隆过滤器就成了一个非常好的选择,Redis可以通过第三方模块或者自己用Bitmap数据结构来实现布隆过滤器。 布隆过滤器的原理稍微复杂一点,但你可以简单理解为:它使用多个不同的哈希函数,对同一条数据(比如内容本身)进行哈希计算,得到多个哈希值,然后把位图中对应的这几个位置都设置为1。 判断重复时,同样用这些哈希函数计算新数据的哈希值,然后检查位图中这些位置是否都是1,如果都是1,那么很可能是重复数据(存在极小的误判概率);如果有一个不是1,那么肯定不是重复数据。 这里第三个,也是最重要的细节就是:布隆过滤器不是100%准确的,它存在误判的可能(False Positive)。 这意味着它可能会把一些新的数据误判为重复数据,但绝不会把重复的数据漏掉判成新的,所以它适用于那些“可以接受漏掉一点点重复数据,但绝对不能把重复数据当新的”的场景,比如新闻去重、推荐系统去重等,你需要根据能容忍的误判率来调整哈希函数的个数和位图的大小。
实际操作中的其他细节
- 键的过期时间(TTL): 你是否需要永久去重?全球唯一”这种需求,很多时候我们只需要在一段时间内去重,一个用户一天内不能重复抽奖”,这时候一定要给你设置的Redis键加上过期时间(
EXPIRE命令),否则数据会无限累积,最终撑爆内存。 - 选择哪种唯一标识? 直接用原始数据(如长文本)作为Set的成员或哈希的输入通常很傻,因为占空间大、计算慢,通常的做法是提取数据的MD5或SHA1等哈希值作为指纹。但第四个细节是:要意识到哈希碰撞的风险。 虽然概率极低,但理论上两个不同的数据可能产生相同的哈希值,对精准度要求100%的场景,如果担心碰撞,可以在哈希判重后,再对比一次原始数据(如果原始数据可获取的话)。
- 性能考量: Set的SADD和Bitmap的SETBIT/GETBIT都是O(1)时间复杂度的操作,速度非常快,布隆过滤器的多次哈希计算会稍微耗一点CPU,但整体性能依然很高,去重操作通常是整个业务流程中的一个环节,要确保它不会成为瓶颈。
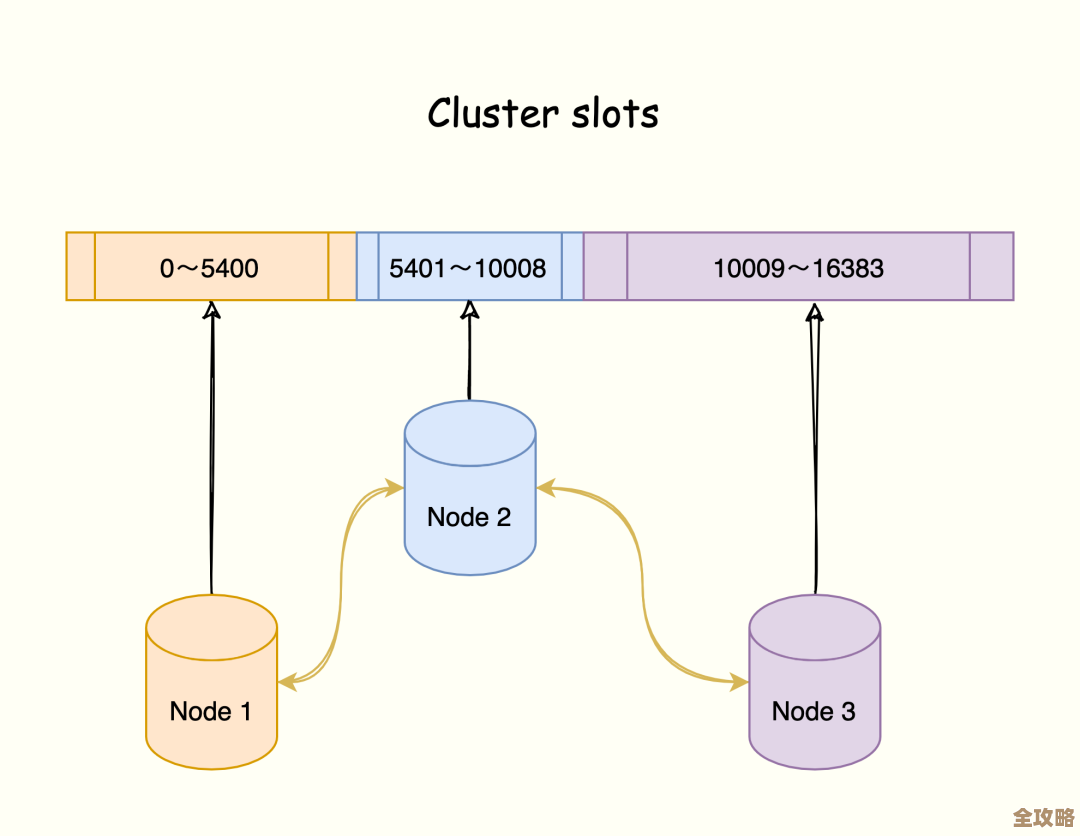
- 数据持久化与集群: 如果你的Redis配置了持久化(RDB/AOF),这些去重数据是会落盘的,重启后不会丢失,在Redis集群模式下,你需要确保同一个去重键下的所有操作都落在同一个哈希槽上,通常可以通过使用相同的键名或使用哈希标签(hash tag)来保证。
没有一种方法能通吃所有场景,选哪种取决于你的核心需求:100%精准且数据量不大用Set;海量连续整数ID用Bitmap;海量非数字ID且能接受微弱误判用布隆过滤器,务必处理好键的过期、标识的选择和集群环境下的兼容性这些实操细节。

本文由革姣丽于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82121.html