数据库性能优化里那些读写分离和分库分表到底怎么搞才靠谱

主要整合自阿里巴巴开发规范、业界资深工程师的实践经验分享以及《高性能MySQL》等经典书籍中的核心思想)
咱们得搞清楚一个基本问题:什么时候才需要考虑读写分离和分库分表?很多人一上来就想搞个大新闻,其实完全没必要,如果你的数据库数据量不大,比如就几百万条记录,平时访问量也不高,那么一台配置好点的数据库服务器完全够用,盲目上分库分表,只会让系统变得无比复杂,简直是自找麻烦,靠谱的第一步是:先尽力优化单机数据库,这包括优化你的SQL查询语句(比如避免使用SELECT *,合理使用索引),调整数据库的配置参数(比如缓冲池大小),升级硬件(比如换SSD硬盘),只有当单机性能确实遇到瓶颈,比如磁盘IO(读写速度)持续很高、CPU使用率长期居高不下,或者数据量真的大到单台机器快存不下了,这时候你再考虑下面的方案。
第一部分:读写分离怎么搞才靠谱?

读写分离的核心思想特别简单,就八个字:主库写数据,从库读数据,你想象一下,一个公司里,老板(主库)负责拍板做决策(写入、更新、删除数据),而一大堆秘书(从库)负责把老板的决策传达下去,并回答各部门的咨询(读取数据),这样老板就能专心处理最重要的写操作,不会被杂七杂八的读请求打扰。
具体怎么搞呢?
- 搭建主从复制:这是基础,你需要先搭建至少一主一从的数据库架构,主库和从库之间通过数据库自带的复制功能(比如MySQL的binlog复制)保持数据同步,主库每执行一个写操作,都会记录一个日志,从库就不断地拉取这个日志,然后在自己身上重放一遍,这样数据就同步了。
- 应用程序改造:这是关键,你的程序代码不能再像以前一样只连一个数据库了,你需要引入一个机制,能够识别哪些SQL是写操作(INSERT, UPDATE, DELETE),把它发给主库;哪些是读操作(SELECT),把它发给从库,通常有两种做法:
- 使用中间件:在应用程序和数据库之间加一层代理(比如ShardingSphere、MyCat等),应用程序把所有SQL都发给这个中间件,由它来智能地路由到主库或从库,这对业务代码的侵入性最小,但需要维护中间件本身。
- 在代码中封装数据源:这是更常见、也更灵活的方式,你可以用一些开源的框架(比如Java领域的ShardingSphere的JDBC驱动模式),或者在代码里自己封装两个数据源(一个主数据源,一个或多个从数据源),然后通过注解(如
@Master、@Slave)或者根据方法名等方式,来决定使用哪个数据源,这种做法性能更好,但需要修改代码。
靠谱的注意事项:

- 延迟问题:这是读写分离最大的坑,主库写完数据,到从库同步完数据,这中间有个极短的时间差,叫做“主从延迟”,如果你刚在主库写完,立刻就去从库读,很可能读不到刚写的数据,解决方法是:对于写完马上要读的场景,强制走主库,比如用户注册后立刻跳转到个人中心,这个查询就应该强制发给主库,确保数据一致性。
- 从库负载均衡:当你有多个从库时,读请求要在它们之间均匀分配,避免某个从库压力过大。
- 从库高可用:某个从库宕机了,读请求应该能自动切换到其他健康的从库上。
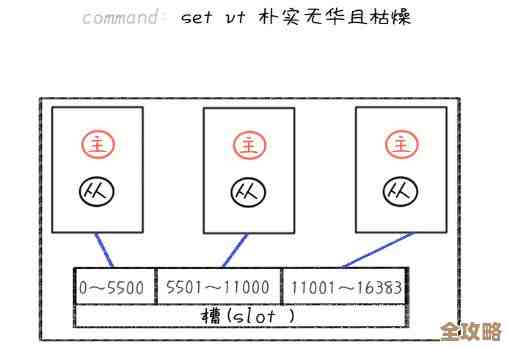
第二部分:分库分表怎么搞才靠谱?
当你的数据量单台机器实在扛不住了,比如单表有了几千万甚至上亿行数据,查询速度变得巨慢,这时候就要考虑分库分表了,它比读写分离更复杂,可以分开看:
分表
顾名思义,就是把一张大表拆成多张小表,比如原来的user表有1亿条数据,你可以把它拆成100张表,每张表大约100万条数据,分别叫user_00, user_01, ... , user_99。

- 怎么分?—— 分片键的选择是灵魂,你需要选择一个列作为分片的依据,这个列叫“分片键”,常用的有:
- 用户ID(UID):这是最常用的,比如按UID对100取模(求余数),算出来是几,数据就存到第几张表,这样同一个用户的数据都会落在同一张表里,查询某个用户的信息很快。
- 时间:比如按月份分表,2023年1月的数据在
orders_202301,2月的在orders_202302,特别适合日志、流水记录等按时间查询的场景。 - 地理区域:比如按城市ID分。
- 靠谱建议:分片键一定要选择查询条件中经常出现的那个字段,否则一旦你的查询条件里没有分片键,就需要去所有表里扫描一遍(这叫“全库扫描”),性能会灾难性的下降。
分库
分库是在分表的基础上,更进一步,不光是把表拆开,还把拆出来的表分布到不同的数据库服务器上,比如你把user_00到user_49这50张表放在数据库A服务器上,user_50到user_99放在数据库B服务器上,这样做的最大好处是进一步分散了磁盘IO和CPU的压力。
分库分表一起搞,靠谱的操作步骤:
- 慎重选择分片策略:这是最核心的决策,一旦上线,几乎无法修改,除了上面提到的取模,还有范围分片(如ID 1-1000万在库1,1000万-2000万在库2)、一致性哈希等,要综合考虑数据均匀性和未来扩容的便利性。
- 使用成熟的中间件:强烈不建议自己从零开始写分库分表的逻辑,坑太多了,应该使用像ShardingSphere、MyCat这样的成熟开源中间件,它们帮你解决了SQL解析、路由、结果合并、事务管理等复杂问题。
- 处理好分布式事务:这是难点,当一次操作涉及更新多个库的数据时,如何保证要么全部成功,要么全部失败?单机数据库的本地事务不好使了,需要考虑使用柔性事务/最终一致性方案(如通过消息队列)或者分布式事务中间件(如Seata)。
- 面对跨库查询:原本一个
JOIN查询就能搞定的事,分库分表后可能变得非常困难,因为相关联的数据可能分布在不同的库、不同的机器上,常见的解决思路是:- 业务上避免: redesign你的业务,尽量减少甚至避免多表关联查询。
- 字段冗余:把一些常用的关联查询字段冗余到主表中,用空间换时间。
- 全局表/广播表:对于一些数据量小、更新少的字典表(如城市列表),可以在每个分库中都存一份完整的副本。
- 分开查询,应用层合并:先查A表拿到一批ID,再根据这批ID去查B表,最后在程序内存里把数据组装起来。
怎么搞才靠谱:
- 循序渐进:先优化单机 -> 再读写分离 -> 最后才是分库分表,不要一步到位。
- 技术选型:优先选择经过大规模实践检验的开源中间件,如ShardingSphere,而不是自己造轮子。
- 设计先行:分片键和分片策略的选择是重中之重,需要和业务紧密结合,反复推演。
- 接受妥协:分库分表在获得扩展性的同时,必然会牺牲掉一些东西,比如跨库事务的强一致性、便捷的关联查询,你需要和业务方沟通好,让大家理解并接受这些权衡。
最后记住,没有一劳永逸的银弹,无论是读写分离还是分库分表,都大大增加了系统的复杂度,对开发和运维的要求也更高,除非迫不得已,不要轻易动用这把“手术刀”。
本文由芮以莲于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82487.html