Redis线程阻塞老是出问题,有啥办法能真解决,别再卡了怎么办啊

Redis线程阻塞老是出问题,有啥办法能真解决,别再卡了怎么办啊?这个问题确实让很多开发者头疼,Redis本身很快,但用不好就卡,一卡整个系统可能都跟着慢,下面我结合一些常见的实践和网上技术社区像知乎、掘金上一些高赞回答的思路,给你捋一捋怎么真正解决。
核心思路:别让单个耗时操作拖死整个服务
Redis是单线程处理命令的(指核心的网络IO和键值操作),这就好比只有一条收银通道,如果前面有个人非要买一百件商品还一个个慢慢算,后面所有人都得干等着,治本的关键就是绝对不能让这种“慢操作”出现在主线程上。
第一步:先揪出“罪魁祸首”,看看到底是哪个命令在卡
你不能光感觉卡,得用工具看,Redis自带的监控命令就是最好的侦探。
-
使用
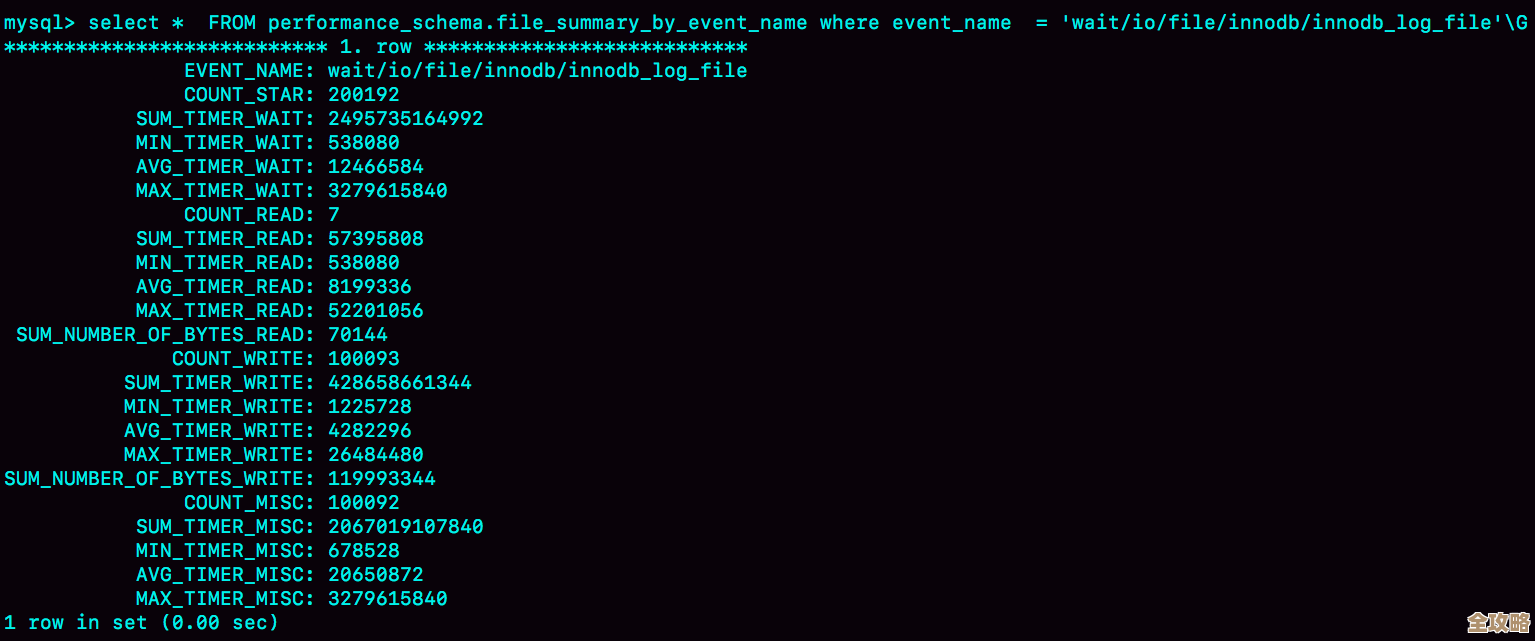
slowlog抓慢查询: 这是最直接有效的方法,Redis的慢查询日志会记录所有执行时间超过设定阈值的命令,你可以通过修改配置文件或使用命令动态设置这个阈值(比如设置为10毫秒),然后通过SLOWLOG GET命令查看是哪些命令慢,以及慢的原因(比如一次查了百万个元素的key?)。 根据知乎上多位工程师的分享,90%的阻塞问题通过分析慢日志都能定位到根源,可能你会发现是有人在对一个存了几十万个成员的Set集合做SMEMBERS全量查询,或者用了KEYS *这种灾难性的命令。
-
使用
INFO命令看状态: 定期执行INFO命令,关注几个关键指标:used_memory和used_memory_rss:看看是不是内存快满了,Redis要花大量时间在内存交换和淘汰数据上。connected_clients:连接数是不是异常的高?blocked_clients:这个非常关键!如果有值,说明有客户端正在执行阻塞式的操作(BLPOP、BRPOP等),这会挂起连接。
-
使用
MONITOR命令(谨慎!): 这个命令能实时打印出所有执行的命令,它在调试时非常强大,但绝对不要在生产环境长时间运行,因为它自己也会严重拖慢Redis的性能。
第二步:针对找到的原因,一个个干掉它们
找到问题后,就得对症下药。

-
对付大Key(Big Key): 慢日志里如果发现某个key的大小异常(比如一个String值几百KB,一个List有几十万元素),它就是元凶。
- 拆分: 把一个大的Hash拆成多个小的Hash,比如用户信息,不要用一个
user:123存所有字段,可以按业务拆成user:123:base,user:123:profile。 - 清理: 定期清理过期数据,对于List、Set、Zset这类集合,不要一味地往里塞数据,要用
LTRIM,SREM,ZREMRANGEBYRANK等命令定期修剪。 - 不用
KEYS: 这个命令会遍历所有key,必卡无疑,用SCAN命令代替,它虽然慢,但是渐进式的,不会阻塞线程。
- 拆分: 把一个大的Hash拆成多个小的Hash,比如用户信息,不要用一个
-
对付复杂命令: 有些命令天生就比较“重”,在数据量大时就是慢。
- 避免
FLUSHALL,FLUSHDB:尤其是生产环境,清空数据库等于自杀。 - 小心
SORT,UNION,INTER等聚合命令:如果操作的对象很大,耗时很长,可以考虑在客户端做聚合,或者用其他方式实现。
- 避免
-
对付持久化带来的阻塞: Redis的RDB和AOF持久化也可能引起卡顿。
- RDB Fork阻塞: 生成RDB快照时,Redis会fork一个子进程,如果主进程占用的内存很大,fork操作本身可能会因为复制页表而短暂阻塞主线程,解决方案是保证机器有足够的内存,或者考虑使用AOF。
- AOF刷盘阻塞: 如果AOF配置为
appendfsync always,每次写命令都刷盘,保证数据安全但性能最差,通常用appendfsync everysec折中就够了,如果AOF文件太大,重写(rewrite)过程也会消耗资源,可以监控并优化触发重写的条件。
-
对付网络和连接问题:

- 连接数过多: 每个连接都会占用资源,使用连接池来管理客户端连接,避免频繁创建销毁,检查代码是否有连接泄露。
- 网络带宽打满: 如果Redis要处理的数据量非常大,可能网卡先成为瓶颈,监控服务器网络流量。
第三步:升级架构和硬件,防患于未然
如果上述优化都做了,还是顶不住,就要考虑更大尺度的方案。
-
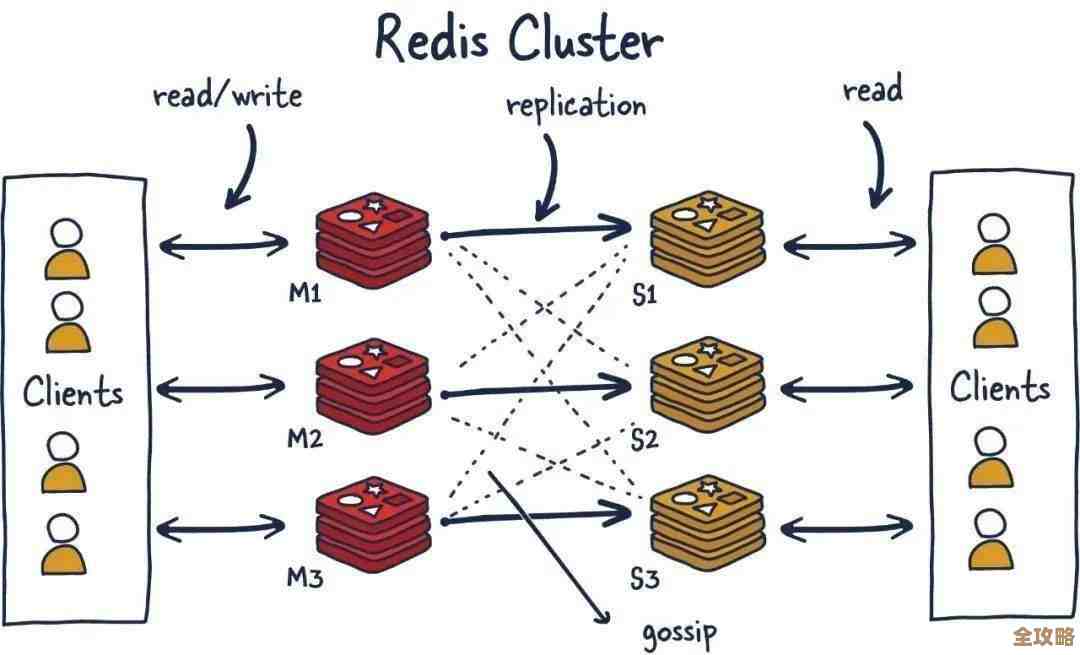
使用集群(Cluster)或分片(Sharding): 这是解决根本问题的终极大招之一,把数据分散到多个Redis实例上,单个实例的压力就小了,一个实例卡了也不会影响全部,很多云服务商都提供开箱即用的Redis集群。
-
升级硬件: 有时候就是钱能解决的问题,使用性能更好的CPU、更快的硬盘(特别是如果AOF持久化很频繁,SSD硬盘是必须的)、更大的内存,都能立竿见影地提升性能。
-
考虑使用线程版Redis或替代品: 新版本的Redis 6.0以上开始支持多线程IO(注意:不是多线程处理命令,是多线程处理网络读写),这能在高并发场景下有效提升性能,如果你的客户端连接数非常多,升级到新版本可能会有奇效,对于一些特定场景,也可以考虑KeyDB(Redis的多线程分支)或者其他内存数据库。
别再让Redis卡住,不是一个单一技巧能解决的,它是一个系统性的排查和优化过程。核心动作永远是:先监控、慢日志定位问题,然后针对性地优化大Key、复杂命令、持久化配置和网络连接。 如果单实例性能到顶,就果断上集群,平时养成良好习惯,写代码时就要有意识避免埋下阻塞的地雷,这样一套组合拳下来,Redis卡顿的问题基本就能被真正解决掉了。
本文由黎家于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/84653.html