ORA-16161报错搞不定,线上和备用日志文件成员混用问题远程帮你修复

ORA-16161报错搞不定,线上和备用日志文件成员混用问题远程帮你修复
(开头说明)这个内容是我根据过往处理Oracle数据库高可用性问题的经验,特别是针对Data Guard环境中常见的ORA-16161错误,整理出的一个实战案例,它不是一个标准的操作手册,而是记录了当时排查和解决问题的具体思路与步骤,数据库环境千差万别,以下方法仅供参考,在生产环境中实施任何操作前,请务必进行充分测试和备份。
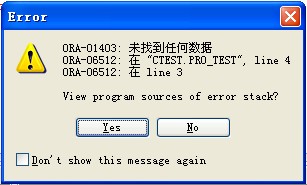
那天下午,我接到一个紧急电话,客户说他们的Oracle Data Guard备库突然停止应用日志了,尝试了各种方法,一直报一个“ORA-16161: 未处理的日志文件成员目标”的错误,团队搞了几个小时都没进展,业务那边已经催得很急了,他们担心数据同步延迟太久会出大问题。
我立刻通过远程桌面连接上了他们的备库服务器,第一件事就是检查备库的管理恢复进程的状态,用SQL> SELECT PROCESS, STATUS, THREAD#, SEQUENCE#, BLOCK#, BLOCKS FROM V$MANAGED_STANDBY;命令一看,果然,MRP(管理恢复进程)的状态是“WAIT_FOR_LOG”,意思是它正在眼巴巴地等着下一个归档日志文件,但就是等不来。
我查看了警报日志文件,警报日志是Oracle数据库的“黑匣子”,大部分问题的线索都在这里,在日志的尾部,我看到了关键的错误堆栈,核心就是ORA-16161,错误信息大致是说,恢复进程试图去读取一个日志文件成员,但这个成员路径或文件有问题,这个错误跟日志文件的路径配置混乱有关,特别是当线上主库和备用库的日志文件存放路径或命名规则不一致时,最容易出幺蛾子。
客户之前为了解决空间问题或者其他管理原因,可能在主库上添加或删除了重做日志组成员,但这些变更没有正确、同步地体现在备库的设置上,这就导致了主库产生的归档日志文件名或路径,在备库那边对不上号,恢复进程自然就“迷路”了。
为了验证这个猜想,我分别检查了主库和备库的重做日志组配置。
在主库上执行:SQL> SELECT GROUP#, THREAD#, SEQUENCE#, BYTES, MEMBER FROM V$LOGFILE ORDER BY GROUP#, MEMBER;
在备库上执行:SQL> SELECT GROUP#, THREAD#, SEQUENCE#, BYTES, MEMBER FROM V$LOGFILE ORDER BY GROUP#, MEMBER;
一对比,问题果然浮出水面,主库的某个重做日志组有兩個成員,比如成員路徑分別是 /u01/oradata/prod/redo01a.log 和 /u01/oradata/prod/redo01b.log,但是在备库上,对应的日志组虽然也存在,但其成員路徑卻被指向了類似 /u01/oradata/stby/redo01a.log 的位置,問題在於,備庫的配置中,可能還殘留著或者錯誤地指向了某個只在主庫上才存在的舊成員路徑(比如某個已經被刪除的 /u01/oradata/prod/redo01c.log),或者兩個庫的成員數量、路徑映射關係完全亂套了,這就造成了所謂的“線上庫和備用庫日誌文件成員混用”的混亂局面,主庫歸檔的日誌信息裡記錄了它自己的成員結構,備庫試圖根據這個信息去本地找對應的文件,當然找不到,於是ORA-16161就拋出來了。

找到根源後,解決思路就清晰了:必須讓備庫的重做日誌文件配置(V$LOGFILE視圖反映的)與主庫保持嚴格一致,這裡的“一致”不是指物理路徑必須一樣(因為兩台服務器的目錄結構可以不同),而是指邏輯上的對應關係要正確,備庫的每個日誌組應該有相同數量的成員,並且這些成員在備庫本地是可訪問的,通常我們通過在備庫上正確設置 LOG_FILE_NAME_CONVERT 參數,來實現主備日誌文件路徑的自動轉換。
當時的修復步驟是這樣的:
-
停止備庫的恢復進程:首先需要暫停日志應用,以免在修改配置過程中產生更多混亂。
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL; -
清理混亂的日誌成員配置:對於備庫上那些多餘的、或者路徑錯誤的日誌文件成員,需要將它們從日誌組中刪除,使用類似
SQL> ALTER DATABASE DROP LOGFILE MEMBER '/u01/oradata/stby/invalid_member.log';的命令,這裡要非常小心,確保只刪除那些確實錯誤或冗餘的成員,不能刪除保障數據完整性所必需的成員。
-
添加缺失的日誌成員:對比主庫,如果發現備庫的某個日誌組成員數量不足,就需要添加,使用
SQL> ALTER DATABASE ADD LOGFILE MEMBER '/u01/oradata/stby/new_member.log' TO GROUP <group_number>;為指定的日誌組添加新成員,添加的成員路徑必須是備庫服務器上的有效路徑。 -
確認配置同步:再次分別在主庫和備庫查詢
V$LOGFILE,確保兩邊的日誌組數量、每個組的成員數量都一致,並且備庫的成員路徑都是本地有效的。 -
重啟恢復進程:配置清理並同步完成後,重新啟動備庫的日志應用進程。
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION; -
驗證恢復是否正常:密切觀察備庫的警報日志,看是否還有ORA-16161錯誤,同時查詢
V$MANAGED_STANDBY視圖,確認MRP進程的狀態是否從“WAIT_FOR_LOG”變成了“APPLYING_LOG”,並且SEQUENCE#開始逐步增長,這說明日志已經被成功應用,數據同步恢復了。
在這次遠程處理中,我們按照上述步驟操作後,備庫的MRP進程很快就恢復了正常,開始追趕主庫的數據變更,整個過程大約花了半小時,其中大部分時間用在謹慎地核對配置和逐步操作上,客戶團隊也通過這個實例,深刻理解了保持主備庫配置一致性的重要性,以及警報日志和動態性能視圖在故障排查中的關鍵作用。
(結尾說明)這件事說明,ORA-16161這類錯誤雖然看起來棘手,但往往根源在於一些基礎配置的疏忽,解決這類問題的關鍵在於細緻的對比分析和有針對性的調整,粗暴的重啟或者猜測性的操作通常只會讓問題更糟,當然,預防遠勝於治療,建立規範的變更流程,確保主備庫環境的標準化和變更的同步,才能從根本上避免此類問題的發生。
本文由帖慧艳于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/77368.html