Redis集合命令怎么快速看懂用好,工作效率能不能蹭蹭涨就靠它了

要快速看懂并用好Redis的集合命令,关键在于别把它想得太复杂,你就把它当成一个实实在在的“袋子”,这个袋子有几个核心特点:里面装的东西都是唯一的(不允许重复),而且没有固定的顺序,抓住这个核心形象,再去看命令,就清晰多了。
(来源:Redis官方文档对Set数据结构的定义)
最常用、必会的几个核心命令
这几个命令是你每天工作都会碰到的,务必记牢。
-
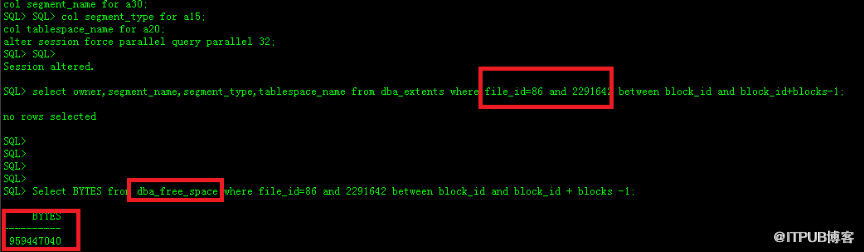
SADD key member [member ...]:往袋子里扔东西。 这是最基础的操作,你有一个叫user:1000:followers的袋子,用来存放用户1000的所有粉丝ID,当有新粉丝(ID为2000)关注时,你就执行SADD user:1000:followers 2000,如果粉丝ID已经存在袋子里了,这次操作就不会重复添加,保证了唯一性,你可以一次性扔多个东西进去,非常高效。 -
SMEMBERS key:把袋子里的所有东西都倒出来看看。 你想看看用户1000到底有哪些粉丝,就执行SMEMBERS user:1000:followers。但是要注意:这个命令会一次性返回集合的所有成员,如果这个袋子特别大(比如有几百万粉丝),这个操作可能会比较耗时,在生产环境下要谨慎使用,避免阻塞其他请求,对于大集合,我们通常用SSCAN来分批查看,这个后面会提到。
-
SISMEMBER key member:检查某个东西在不在袋子里。 这是判断成员是否存在的主力命令,速度极快,你想判断用户2000是不是用户1000的粉丝,SISMEMBER user:1000:followers 2000,返回1表示“是”,返回0表示“不是”,这个操作在检查权限、判断用户是否已投票等场景下非常有用。 -
SREM key member [member ...]:从袋子里拿走东西。 对应添加,就是删除,用户2000取消关注了,那就SREM user:1000:followers 2000,把这个粉丝ID从袋子里移除。 -
SCARD key:数数袋子里有多少个东西。SCARD user:1000:followers会直接返回一个数字,告诉你用户1000的粉丝数量,这个操作也非常快,常用来做计数统计。
让集合发挥威力的“魔法”命令:集合运算
如果Redis集合只是简单的存和取,那它的魅力就减半了,它最厉害的地方在于能对多个“袋子”进行数学上的集合运算。

(来源:Redis官方文档对Set操作的介绍)
-
交集:
SINTER key [key ...]场景:找出共同好友,用户A的好友袋子是friends:A,用户B的好友袋子是friends:B。SINTER friends:A friends:B的结果就是A和B的共同好友列表。 -
并集:
SUNION key [key ...]场景:合并标签,一篇文章可能被打上“科技”、“编程”的标签(存于article:123:tags),另一篇文章被打上“科技”、“人工智能”的标签(存于article:456:tags),如果你想找出所有涉及到的唯一标签,SUNION article:123:tags article:456:tags会返回[科技, 编程, 人工智能]。 -
差集:
SDIFF key [key ...]场景:推荐可能认识的人,计算“用户B的好友”减去“用户A的好友”,也就是SDIFF friends:B friends:A,得到的结果就是用户B有而用户A没有的好友,这些就是系统可以推荐给A的“可能认识的人”。
更强大的操作:以上三个命令都有对应的“存储版”,即 SINTERSTORE, SUNIONSTORE, SDIFFSTORE,它们不是直接返回结果给你看,而是把运算结果存到一个新的Key里,这在需要重复使用运算结果时,能节省大量计算资源。
处理大集合和高级技巧
-
SSCAN key cursor [MATCH pattern] [COUNT count]:安全地查看大袋子。 再次强调,对于可能有成千上万成员的集合,不要直接用SMEMBERS。SSCAN命令允许你像翻书一样,一页一页地遍历整个集合,不会长时间占用服务器资源。SSCAN user:1000:followers 0 MATCH 15* COUNT 100表示从游标0开始,查找以“15”开头的成员,每次返回大概100个。 -
SPOP key [count]:随机弹出东西。 因为集合是无序的,所以随机操作非常高效,这个命令非常适合做抽奖,比如抽奖池是lottery:pool,SPOP lottery:pool 3会随机弹出3个中奖者,并且同时将他们从奖池移除,保证不会重复中奖。 -
SRANDMEMBER key [count]:随机看看,但不拿走。 和SPOP类似,也是随机获取,但不会删除成员,适合做“随机展示”之类的功能。
如何让工作效率蹭蹭涨?
- 建模时多想想“唯一性”和“关系”:遇到需要去重、判断是否存在、找共同点/差异点的业务场景,第一时间考虑使用集合。
- 活用集合运算:这是Redis集合的精髓,很多在代码里需要写循环、比较才能实现的复杂逻辑,用
SINTER,SUNION等命令一行就能解决,性能天差地别。 - 注意命令的陷阱:牢记
SMEMBERS对大数据量的风险,用SSCAN替代,知道SPOP和SRANDMEMBER的区别。 - 组合使用:比如先用
SINTERSTORE把交集结果存起来,再用SCARD快速得到共同好友的数量,再用SMEMBERS或SSCAN列出列表。
当你把这些命令和具体的业务场景(用户标签、社交关系、抽奖活动、数据去重、排行榜辅助等)结合起来反复使用后,你会发现处理数据的思路变得更清晰,代码更简洁,效率自然就上去了,关键就是多实践,把这个“袋子”的工具用熟。
本文由符海莹于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/77369.html