关系型数据库在存储和管理空间数据时到底是怎么安排结构的,有哪些方法和特点呢

关系型数据库,比如我们熟知的MySQL、PostgreSQL、Oracle等,它们最初是为处理表格、数字和文本这类规整数据设计的,核心是行和列,但当要处理空间数据,比如地图上的一个点、一条河流的边界线、或者一个行政区的范围时,这些不规则的几何形状就和传统的数字、文本很不一样了,为了解决这个问题,业界发展出了一套方法和标准,核心就是简单特征模型,这个模型由开放地理空间联盟(OGC)制定,它像是一本说明书,告诉数据库厂商应该如何表示和操作这些空间数据。(来源:开放地理空间联盟OGC的简单特征访问规范)
具体到数据库内部是怎么“安排结构”的,主要有两种方法:
第一种方法叫做二进制大对象存储,这是最主流和标准化的方法,它的思路是:既然空间数据(也叫几何数据)结构复杂,不如把它当作一个整体来对待,数据库会在表中专门开辟一列,比如叫“geom”或“shape”,这一列的数据类型不是普通的整数或字符串,而是一种特殊的“几何类型”,当你要存储一个多边形时,数据库会使用一套内部定义的二进制格式,将这个多边形的所有顶点坐标、边界线顺序、以及它是什么类型(点、线、面)的信息,打包成一个数据包,然后整个存入这个“几何类型”的列中。

这种方法的好处是高效且功能强大,因为数据是二进制存储的,所以读写速度快,更重要的是,数据库厂商会为这种几何类型开发一系列专用的函数,比如计算两个点之间的距离(ST_Distance)、判断一个点是否在一个多边形内(ST_Within)、或者计算两个图形相交的部分(ST_Intersection),你在查询时,可以直接在SQL语句里调用这些函数,就像你使用“SUM”求和函数一样自然,你可以写一句SQL:“查找所有距离某个地标500米内的学校”,数据库会自行解包那些二进制几何数据,进行空间计算后返回结果。(来源:PostGIS、Oracle Spatial等主流空间数据库扩展的文档)
第二种是早期或一些简易系统中使用的方法,叫做几何分解存储,这种方法不把几何图形当作一个整体,而是把它拆解成最基础的零件——坐标点,要存储一条折线,你需要在数据库里设计两张表,一张是“线表”,记录这条线的基本信息,比如线路ID、名称,另一张是“点表”,里面包含坐标点ID、所属线路ID、X坐标、Y坐标,这样,一条线就由“点表”中多个具有相同线路ID的点记录顺序连接而成。

这种方法的好处是结构非常清晰,利用关系型数据库的多表关联和索引能力,理论上可以表示任何复杂的图形,但它的缺点也非常明显:极其繁琐和低效,你想判断两条线是否相交,需要先通过线路ID从点表中取出所有点,在应用程序里重构出两条线,然后再进行几何计算,这个过程中涉及大量的表连接和数据传输,对于复杂的空间查询来说,性能开销巨大,在现代的空间数据库应用中,这种方法基本已经被二进制大对象存储所取代,除非是在处理一些极其特殊或非标准的几何数据模型时。(来源:数据库教科书及早期GIS系统架构分析)
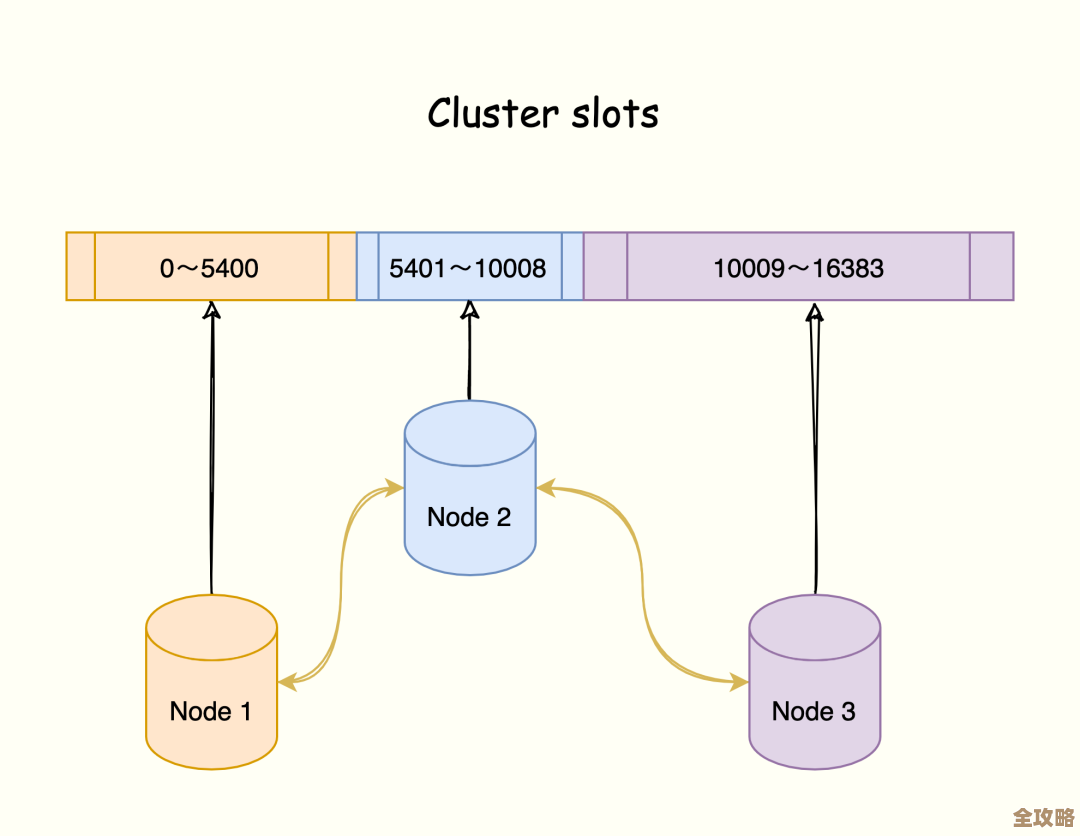
除了存储结构,空间数据管理还有一个至关重要的特点:空间索引,想象一下,在一个存有全国所有道路的数据库中,你想查询“北京市海淀区中关村附近的所有餐厅”,如果没有索引,数据库就得傻傻地计算你的查询位置与全国每一条道路的距离,这叫做“全表扫描”,速度慢得无法接受,空间索引就是为解决这个问题而生的,它不像书本的目录按页码排序,而是按照空间位置来组织数据,最常见的空间索引是R-Tree(R树),它的原理类似于把地图先划分成几个大区域(比如华北、华东),华北区再细分北京、天津等,北京市再细分各区……这样形成一个层次结构,当进行查询时,数据库可以快速排除掉那些与查询区域完全不相干的大块数据,只精确定位到可能相关的少量数据块进行精细计算,从而极大提升查询速度。(来源:关于空间数据库索引技术的学术论文,如R-Tree索引的原型论文)
关系型数据库管理空间数据,核心是通过引入OGC标准的几何数据类型,采用二进制大对象的方式将复杂图形整体存储,并配以一系列强大的空间函数进行查询分析,依赖R-Tree等空间索引技术解决海量空间数据下的快速检索问题,这种方法既利用了关系型数据库成熟稳定、支持标准SQL的优势,又通过扩展赋予了它处理空间信息的能力,使其成为地理信息系统(GIS)等领域中坚实的数据管理基础。
本文由酒紫萱于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82130.html