用Redis缓存来搞数据统计,速度快又省资源,感觉挺实用的吧

行,那咱们就直接聊聊用Redis做数据统计这事儿,确实,就像你说的,速度快又省资源,在很多场景下特别实用,你别看它只是个内存数据库,玩起统计来,很多传统数据库还真比不上。
为啥想到用Redis?传统方法有点“笨重”
咱们先回想一下最传统的做法,比如你运营一个App或者网站,想统计一下今天有多少活跃用户,最直接的办法,可能就是让后端服务每次收到用户请求,都往MySQL这类关系型数据库里插一条记录,或者更新一下某个用户的最后活跃时间,等到晚上要出报表了,再写一条挺复杂的SQL语句,SELECT COUNT(DISTINCT user_id) FROM log_table WHERE date = ',这么搞,有两个明显的问题:
第一,对数据库压力太大,每一个用户行为都意味着一次数据库的写操作,用户量一上来,比如每秒有几千上万个请求,数据库可能就扛不住了,容易成为整个系统的瓶颈,跑那种统计查询本身也很耗资源,尤其是数据量大的时候,一个复杂的查询可能会拖慢其他正常业务的操作。
第二,不够灵活,速度慢,老板或者产品经理可能随时想看一眼实时数据,过去5分钟新增了多少用户?”,你要是每次都去扫一遍巨大的日志表,等结果出来,可能好几分钟都过去了,完全谈不上“实时”。
这时候,Redis的优势就体现出来了,因为它把数据都放在内存里,读写速度极快,每秒处理个十万、百万次请求都很轻松,用它来做实时统计,就像是把笨重的大卡车换成了灵活的跑车。
Redis搞统计的几种“法宝”
Redis不是一种单一的数据结构,它提供了好几种不同的“小工具”,针对不同的统计需求,可以选用最合适的那一个。
-
计数:最简单的,用
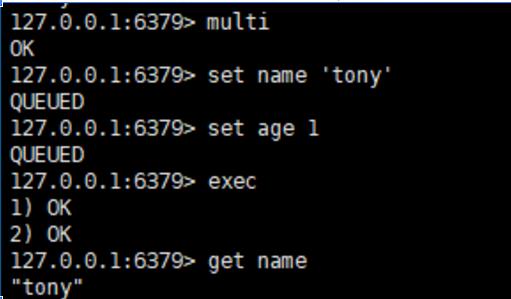
INCR命令 这是最直白的,比如你想统计网站的总访问量,不用想得太复杂,就在Redis里设置一个键,total_visits,每次有人访问网站,就让程序执行一个INCR total_visits命令,这个命令会把值加1,并且是原子性的,也就是说即使有很多人同时访问,也不会出现计数错误,你要看总数,直接GET total_visits,瞬间就拿到结果了,这比往数据库里插一条记录再COUNT(*)快太多了。 -
统计独立用户数:用
HyperLogLog刚才那个是统计总量,但如果我想统计的是“今天有多少独立用户访问过”(也就是UV),用INCR就不行了,因为同一个用户访问多次只能算一次,这时候HyperLogLog就派上用场了,它是个有点“神奇”的数据结构,专门用来估算基数的(就是不重复元素的个数),它的最大优点是极其节省空间,你可能只需要耗费12KB左右的内存,就能统计接近2^64个不重复元素,而且误差率还很低,不到1%。 用法也很简单,用户访问时,执行PFADD daily_uv user_id123,晚上统计时,用PFCOUNT daily_uv就能得到估算的独立用户数,对于绝大多数需要看个趋势的业务场景,这个精度完全够用了,要是用数据库存每个用户的访问记录再去重,存储成本和计算成本都高得多。 -
维护排行榜:用
Sorted Set(有序集合) 比如你要做一个游戏,统计玩家的积分排行榜。Sorted Set简直是为此而生的,每个玩家ID是成员(member),他的积分就是分数(score),玩家得分时,用ZADD leaderboard score player_id来添加或更新分数,要看排行榜?ZREVRANGE leaderboard 0 9立刻就能列出前十名,它内部是用跳跃表实现的,就算数据量很大,排序和取排名的速度也飞快。 -
实时分析数据分布:用
Bitmap(位图) 这个更省内存,比如你想统计用户的一些布尔型属性,像“用户是否完成过某个任务”、“用户是否具有某个标签”,你可以为每一天创建一个很大的Bitmap,每一位代表一个用户ID,如果用户今天活跃了,就把他对应的那一位设为1,这样,你想知道今天有多少用户活跃,一个BITCOUNT daily_active命令就搞定了,想查询某个用户这周是否每天都活跃,也可以用位运算快速得出,Bitmap在存储真假值时,效率非常高。
需要注意的地方
用Redis做统计也不是完美的,有几个点得留心:
- 数据持久化问题:Redis数据主要在内存里,虽然它有持久化机制(RDB快照和AOF日志),但毕竟不像硬盘那么“牢靠”,通常的做法是,用Redis做实时、在线的快速统计和查询,同时定期(比如每小时、每天)把结果同步到MySQL等传统数据库里做永久存储和更复杂的离线分析,两者结合,扬长避短。
- 精度问题:像
HyperLogLog这样的工具,它给出的是近似值,不是100%精确,如果业务要求分毫不差,那可能就不太适合。 - 数据结构选择:用之前得想清楚,你的统计需求到底是什么,选错了数据结构可能效果适得其反。
总结一下
用Redis来做数据统计,核心思路就是“空间换时间”和“利用合适的数据结构”,它把那些频繁、琐碎的统计计算任务,从沉重的传统数据库身上卸下来,通过内存操作快速完成,让你能实时地看到业务数据的变化,对于需要快速反应、高并发场景下的统计需求,比如实时在线人数、分钟级监控、排行榜、用户标签统计等,Redis确实是一个非常实用且高效的工具,感觉它实用,那是因为它真的解决了很多实际开发中的痛点。

本文由颜泰平于2026-01-19发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/83705.html