数据库数据怎么快速又安全地同步到Redis,过程其实没那么复杂

(引用来源:阿里云开发者社区、个人技术博客实践经验总结)
想把数据库里的数据又快又安全地放到Redis里,听起来好像是个大工程,得写很多复杂的代码,担心数据会丢或者出乱子,但其实只要你理清了头绪,整个过程可以很清晰,没那么吓人,核心思想就一句话:根据你的业务场景,选对方法。
第一步:别想一口吃成胖子,先搞清楚你要同步什么?为什么?
这是最重要的一步,决定了你后面用什么工具、怎么写代码,你先问问自己:
- 数据变动的频率高吗? 是每秒都在更新,还是一天只变一两次?
- 对实时性的要求有多高? 是数据库一改,用户立马就要看到最新结果(比如商品库存),还是可以接受延迟几秒甚至几分钟(比如文章阅读数)?
- 你要同步的是全量数据(整个表)还是增量数据(只同步新改动的)? 比如应用刚启动时,可能需要把整个用户信息表加载到Redis,这叫全量同步,而之后用户修改了昵称,只需要同步这一条记录,这叫增量同步。
把这些问题想明白了,我们再来看看具体怎么做。
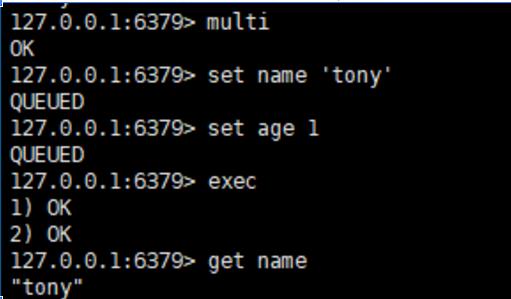
基于应用的“双写”——最简单直接,但要小心
这是最容易想到的方法,就是在你的应用程序代码里,在每次对数据库进行插入、更新、删除操作之后,紧接着写一段代码去更新Redis。

- 怎么做:
- 用户下单成功,你在代码里执行
UPDATE inventory SET stock = stock-1 WHERE item_id=123。 - 紧接着,你就执行
Redis命令:SET inventory:123 最新库存值。
- 用户下单成功,你在代码里执行
- 优点: 非常简单,立马就能实现,实时性也最高。
- 缺点(也是不安全的坑):
- 数据不一致的高风险: 这是最大的问题,如果数据库更新成功了,但紧接着更新Redis的时候网络突然波动了一下,失败了怎么办?那数据库里库存减了1,Redis里还是老数据,用户看到的就是错的。
- 解决方案: 为了解决这个不一致,你可以尝试“事务”或者“先更新数据库,再删除Redis缓存”(这是一种常用模式,下次查询时会自动从数据库加载最新值),但这会增加代码的复杂度。
“双写”适合对一致性要求不是极其苛刻、业务逻辑简单的场景,如果你要用,一定要想好出错后的补偿措施。
基于数据库日志的“CDC”——更可靠,对应用无侵入
这个方法就聪明多了,它不直接从应用层下手,而是去“监听”数据库自己的操作日志(比如MySQL的binlog),数据库的任何变化都会老老实实地记录在这个日志里,我们用一个中间的程序去解析这个日志,然后把这个变化同步到Redis。
- 怎么做:
- 数据库就像一个大老板,他有个秘书(binlog),把他所有的命令(增删改)都记下来。
- 你找一个“中间人”程序(比如Canal、Debezium这类工具),这个中间人不停地去翻看秘书的笔记本。
- 中间人一看:“哦,老板刚刚把id为123的商品库存减了1。” 然后它就直接去Redis里执行
SET inventory:123 新值。
- 优点:
- 对应用透明: 你的业务代码完全不用管同步的事,只需要专心操作数据库就行了,这大大降低了代码的复杂度和bug风险。
- 数据可靠性高: 因为源头是数据库的日志,只要数据库操作成功了,就肯定会被日志记录下来,最终大概率能同步到Redis(中间人程序可以保证重试)。
- 性能影响小: 同步压力从应用服务器转移到了独立的中间人程序上。
- 缺点:
- 需要额外部署和维护一个中间人程序,一开始的搭建和配置需要花点功夫。
- 理解binlog等概念需要一点点数据库基础。
这是目前业界最主流、最推荐用于实现高可靠性实时同步的方式。

定时任务——适合实时性要求不高的场景
如果我们的业务可以接受数据延迟几分钟甚至更久,最热文章排行榜”、“用户积分榜”这种不需要秒级更新的数据,那用定时任务就非常省心。
- 怎么做:
- 写一个脚本,比如每隔5分钟执行一次。
- 这个脚本的任务就是:
SELECT * FROM articles ORDER BY view_count DESC LIMIT 100(查出最热的100篇文章)。 - 然后一把塞给Redis:
Redis命令:ZADD hot_articles 分数1 文章id1 分数2 文章id2 ...。
- 优点: 实现超级简单,逻辑清晰,对数据库和Redis的压力是可控的(因为是一次性批量操作)。
- 缺点: 数据不是实时的,有延迟。
怎么选?
- 要求极高实时性和一致性:优先考虑 方法二(CDC),虽然搭建稍麻烦,但一劳永逸,最稳健。
- 业务简单,变动不频繁,能接受偶尔不一致:可以用 方法一(双写),但一定要写好异常处理。
- 完全不要求实时性,是批量统计类数据:用 方法三(定时任务),最简单高效。
无论用哪种方法,安全同步还有一个通用技巧:给Redis数据设置过期时间(TTL),这就像给数据加了一个“保鲜期”,即使同步过程中出现了什么诡异的数据错误,到了时间它也会自动消失,然后下次查询时系统会从干净的数据库重新加载,起到了一个自我修复的作用。
所以你看,整个过程的关键不在于技术有多高深,而在于你是否能根据自己业务的“脾气”,为它量身选择最合适的那条路,选对了路,剩下的就是一些简单的实践了。
本文由歧云亭于2026-01-19发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/83707.html